ゲノムとは、生物がもつ遺伝情報の総体を指します。そのゲノムは、細胞内のDNAというメディアに格納されています。DNA塩基配列という専門用語がよく使われるように、4種類の核酸分子(A, C, G, Tと略して使われます)が一列に並んだ記号列としてゲノムの情報は保存されています。すなわち、私たちの使っている日本語の文章が、ひらがな、カタカナ、漢字などの文字が並んだ文字列として表されるように、ゲノムもアルファベットとして4種類の記号を用いた文字列として表現されていると考えることができます。そのため、遺伝子言語学というアプローチを提唱する研究者も多くいます。
例えば、私たちの研究室で最近解読した納豆菌のゲノムの一部は下記のような文字列で表されます:
GTGCGTGAAAAAAAATATTATGAATTAGTGGAACAATT
AAAAGACAGAACACAAGACGTAACATTTTCAGCTACAA
AAGCACTAAGTCTTCTTATGCTGTTCAGCAGATATTTG
GTCAATTACACCAATGTCGAATCAGTAAATGACATTAA
TGAGGAATGCGCCAAACATTATTTTAACTACTTAATGA
AAAACCATAAGCGATTAGGAATTAATCTGACAGATATA
AAAAGGTCGATGCATCTAATCAGCGGGTTATTGGATGT
GGATGTAAACCACTATTTAAAGGATTTTTCACTATCGA
ATGTCACGCTGTGGATGACGCAAGAGAGATAA
しかし、ほとんどの人はこの文字列を見ても、そこに何が書かれているかは分からないでしょう。この文字列には、納豆菌が大豆を発酵して「ねばねば」を作り出すために必要な遺伝子の情報が書かれています(図1参照)
図1 納豆菌の顕微鏡写真(左)
蒸した大豆に納豆菌をかけて発酵したもの(右)
さらに、ゲノムを解読する上で難しい問題は、そのデータ量が非常に大きいことです。上の文字列の長さは336文字(専門的には336塩基対)ですが、納豆菌のゲノム全体は409万塩基対なので上記の文字列の約1万2千倍、ヒトの場合はゲノムの大きさが30億塩基対なので約890万倍という非常に大きなデータ量となります。このような膨大なデータを解析するために、比較ゲノムという手法とコンピュータを組み合わせてゲノムの情報を解析するバイオインフォマティクスという研究が活発に行われています。例えば、図2の2つのDNA配列は、結核菌とライ菌というどちらもヒトに感染して病気を引き起こすバクテリアのゲノムの一部ですが、文字列として似ている単語に相当する部分を見つけて比べています。このように似ている単語が多く含まれるDNA配列は同じ内容を意味している文章としてとらえることが出来ます。さらに、ヒトなどを含む高等生物のたくさんのゲノムを丸ごと比較して俯瞰すると図3のようになります。
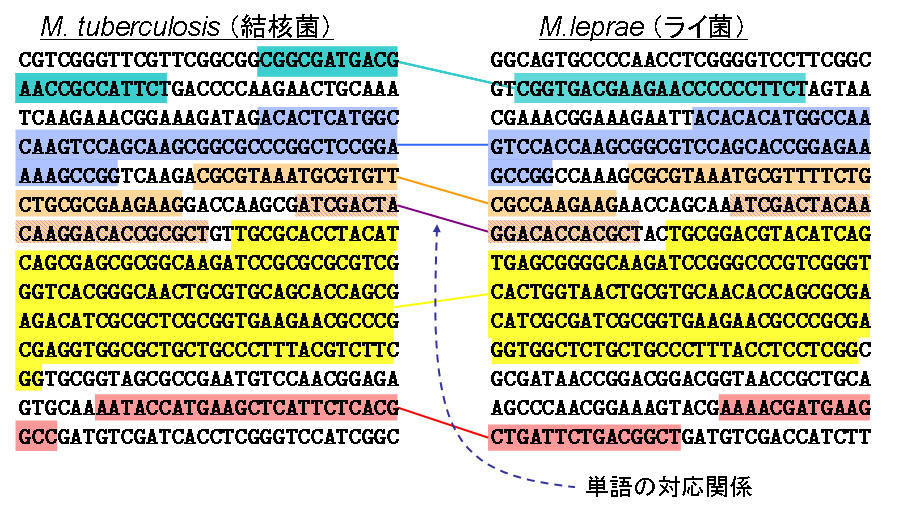
図2 結核菌(左)とライ菌(右)のゲノムの一部のDNA配列。同じ色が塗られている部分は2つの菌の間で似ている部分配列。
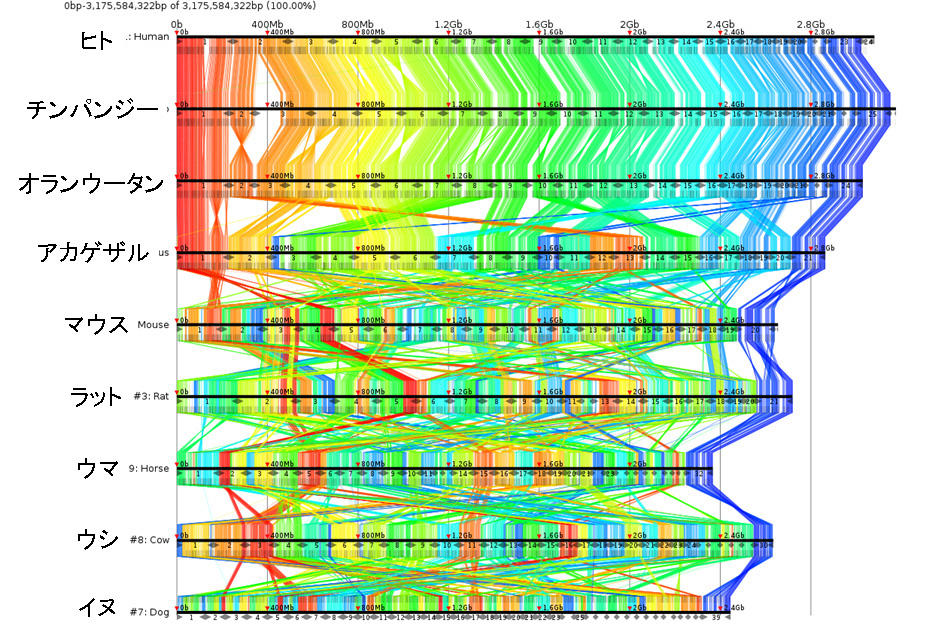
図3 ヒト、チンパンジー、オランウータン、アカゲザル、マウス、ラット、ウマ、ウシ、イヌのゲノムの全染色体を丸ごと比較して単語を抽出した解析結果、同じ色の線が引かれている部分は、ゲノム間で同じ単語が含まれている箇所を示している。このように、ゲノム全体の比較を俯瞰できる。
2010年12月現在、ゲノム配列が決定された生物種の数は真核生物153種、原核生物1,384種の合計1,537種です。また、真核生物で1,689種、原核生物で5,673種のゲノム配列決定プロジェクトが進行中です。そして、地球上には数千万種の生物(どれだけの種が存在するのか正確な数字はまったく分かっていない)が存在していると見積もられています。さらに、同じ種の中でも個体間でゲノムは少しずつ異なっています。これを多型といいますが、ヒトでも親子や兄弟、他人と自分の持っているゲノムは異なります。それが、顔や髪の毛の色の違い、さらにはガンにかかりやすいなどの体質の違いとなって現れます。このように生物一つ一つがゲノムという本を持っているとすれば、地球はそれらのすべてのゲノムの本を集めた「ゲノム図書館」ということができると思います。その膨大な数の本が収納されている図書館には、あなた自身のゲノムの本もありますし、まだ誰も呼んでいない本がたくさん存在します。そして、その中には村上春樹の小説よりも面白い本がきっとあるはずです。


